Understanding AWS Incident Manager On-Call
AWS On-Call is a service that helps organizations manage and respond to incidents quickly and effectively. It’s part of AWS Systems Manager. This document explains the key parts of AWS Incident Manager On-Call—contacts, escalation plans, runbooks, and response plans—in a simple and clear way.
Key Components of AWS Incident Manager On-Call
AWS Incident Manager On-Call relies on four main pieces: contacts, escalation plans, runbooks, and response plans. Let’s break them down one by one.
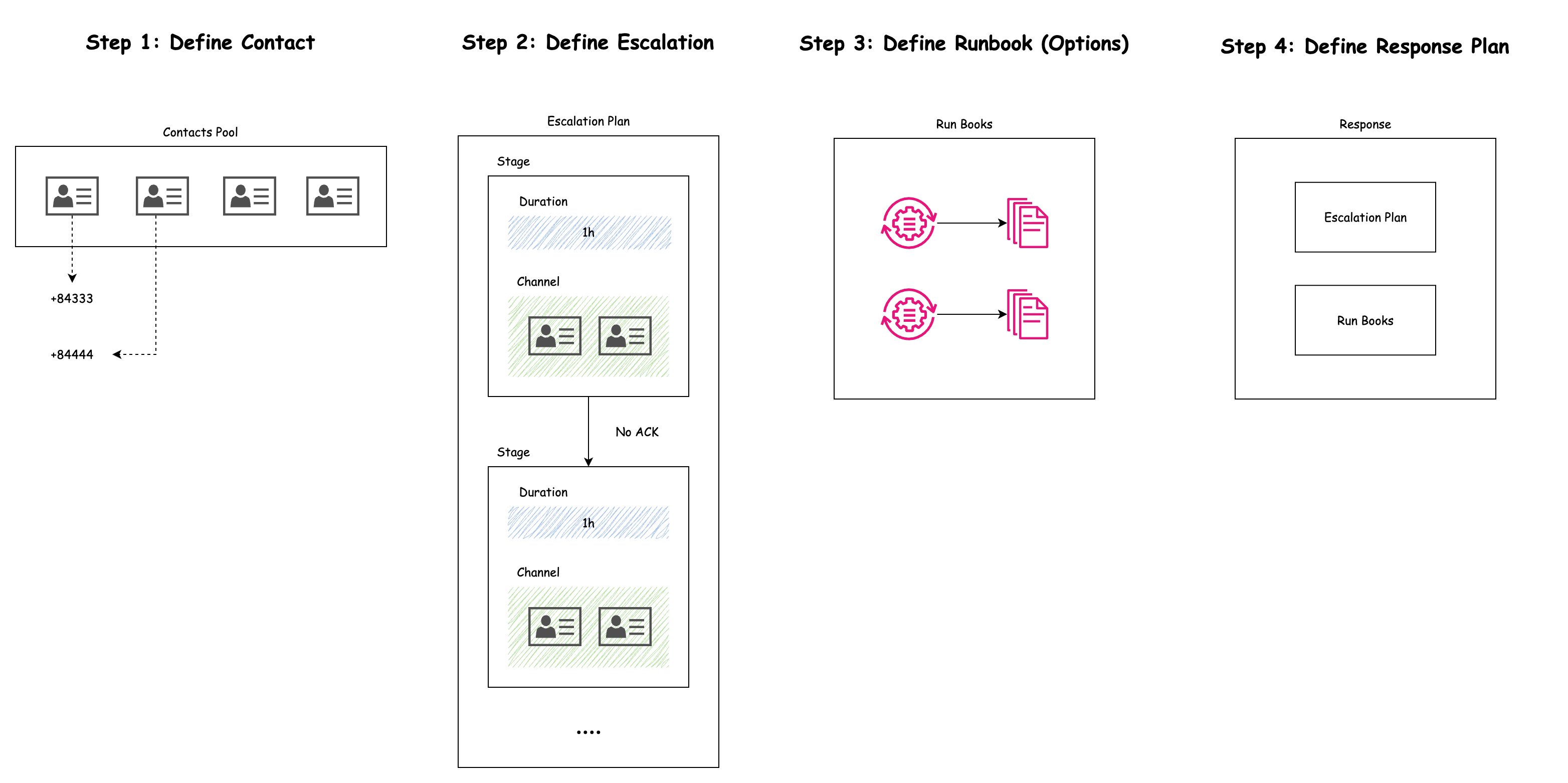
1. Contacts
Contacts are the people who get notified when an incident happens. These could be:
- On-call engineers (the ones on duty to fix things).
- Experts who know specific systems.
- Managers or anyone else who needs to stay in the loop.
Each contact has contact methods—ways to reach them, like:
- SMS (text messages).
- Email.
- Voice calls.
Example: Imagine Natsu is an on-call engineer. His contact info might include:
- SMS: +84 3127 12 567
- Email: natsu@devopsvn.tech
If an incident occurs, AWS Incident Manager can send him a text and an email to let him know she’s needed.
2. Escalation Plans
An escalation plan is a set of rules that decides who gets notified—and in what order—if an incident isn’t handled quickly. It’s like a backup plan to make sure someone responds, even if the first person is unavailable.
You can set it up to:
- Notify people simultaneously (all at once).
- Notify people sequentially (one after another, with a timeout between each).
Example: Suppose you have three engineers: Natsu, Zeref, and Igneel. Your escalation plan might say:
- Stage 1: Notify Natsu.
- Stage 2: If Natsu doesn’t respond in 5 minutes, notify Zeref.
- Stage 3: If Zeref doesn’t respond in another 5 minutes, notify Igneel.
This way, the incident doesn’t get stuck waiting for one person—it keeps moving until someone takes action.
3. Runbooks (Options)
Runbooks are like instruction manuals that AWS can follow automatically to fix an incident. They’re built in AWS Systems Manager Automation and contain steps to solve common problems without needing a human to step in.
Runbooks can:
- Restart a crashed service.
- Add more resources (like extra servers) if something’s overloaded.
- Run checks to figure out what’s wrong.
Example: Let’s say your web server stops working. A runbook called “WebServerRestart” could:
- Automatically detect the issue.
- Restart the server in seconds.
This saves time by fixing the problem before an engineer even picks up their phone.
4. Response Plans
A response plan is the master plan that pulls everything together. It tells AWS Incident Manager:
- Which contacts to notify.
- Which escalation plan to follow.
- Which runbooks to run.
It can have multiple stages, each with its own actions and time limits, to handle an incident step-by-step.
Example: For a critical incident (like a web application going offline), a response plan might look like this:
- 1: Run the “WebServerRestart” runbook and notify Natsu.
- 2: If the issue isn’t fixed in 5 minutes, notify Bob (via the escalation plan).
- 3: If it’s still not resolved in 10 minutes, alert the manager.
This ensures both automation and people work together to fix the problem.
Next, we will provide a step-by-step guide to integrating Versus with AWS Incident Manager for On Call: Integration.